Intelligent Storage
and artificial work documents

Moving on from authentication and into file management next. It is all still part of the drive towards integrating different services and I'm hoping that after I build this part, I can “bundle” them together into a single package that I will call Integrators. So we start with storage: files, images, pdfs, docs, presentations, etc. The fact is that we use files constantly and need to make them available to other people on a regular basis. Whether it's to attach meeting notes to an email, or posting worksheets for an assignment, or adding a class syllabus to your page, we need for users to be able to upload and link files to different objects in our system.
There are multiple ways of uploading files, but they all require a server to store them that has net access and a public link so that we can access them. They also have permissions, but those only apply if you're a user in the system. The goal is to allow maximum flexibility for users to utilize any file they have available in whatever service they use and attach them to any objects in our system that allows for file attachments. Users and permissions are tricky, because in order for the permissions to work, you need to be a user in that service. Google Doc permissions, for example, only really apply if you have a Google account. If you don't there's only read permissions (making it public). This is an issue if you link a google file, but don't give it the right permissions, then the file will be inaccessible to a user w/out a Google account. It's easier if your whole institution has the same suite, then we can all collaborate, but it can still lead to permissions issues if not done correctly.
We also need to address the issue of permanency. This is the #1 problem with linking files and it is a larger issue for us as schools. File permanency is the idea that when you post an assignment, or you turn in an assignment to a class, the file should not be able to change or be deleted anymore. Let's think of this as terms of a Google Doc; the student has an assignment that they submit an essay in a google doc to their class. Once that google doc is “linked”, the student can still change the doc, even though it was submitted. Meaning that changes can still be taking place after the deadline, or even as the teacher is grading the paper. You can also change it after you've gotten a grade, so that information about what you did wrong is lost.
When writing a paper, students are expected to make a rough draft, which then gets marked up, then another draft, then a final one. Each of those drafts holds important historical data about learning. It points out what you were doing wrong so you can look back and learn from your mistakes. When linking a document, those mistakes are erased from history, so a lower grade might have been given, but the paper that was actually assessed is lost, since the user changed the file after the fact.
It's a bigger problem when files can be deleted. If the student submits something, then deletes it in their own service, the link is gone with no way to retrieve it. Same for a teacher posting an old syllabus or class announcements. If the teacher leaves and the account disappears, all the work goes with that account, all the history and artifacts that belonged to the school is now gone. Most systems now a days don't really care about this; They'll expect the users to deal with it, either through document history (usually 30 days), or taking care of not deleting the files. In a lot of cases, especially when the teacher leaves abruptly, the school loses all the work that they put in. They might still have access to the files, but the linking information and the structure of how it was used is lost.
This becomes even more problematic when you add the fact the “submissions” are not really paper-based anymore. There are classes where students are asked to submit videos, or multimedia projects, or high-quality art, etc. Now, actually trying to “capture” these becomes really hard. If anything, just for the space that is required to host these files and all the historical data of documents and assignments. At some point, your school is going to need a lot of space.
Storage Spaces
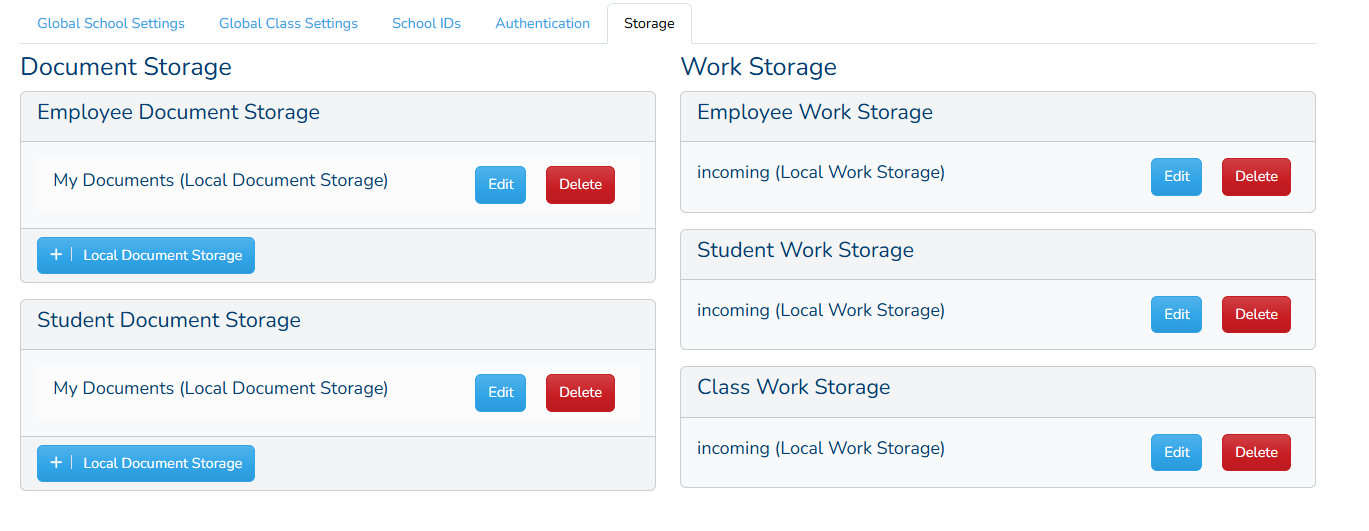
My solution is a two-ponged approach. First, we will create “storage spaces” where an admin can designate storage for certain categories. For example, there should be a storage space for student work, one for teacher uploads, and one for document management. Each of these spaces will be fully configurable and you can use different methods for each. Some examples:
- Student/Teacher/Admin Work Storage:
- It could be a file server that will put in all student work submitted.
- The storage will be server-managed.
- If google, it would match to a google account.
- Document Management
- Can be your own Google account
- If there's a local option, there should be an option to add your own google account.
- The source should be irrelevant
The second prong is the idea of snapshots that will reside faculty-side. On every assignment posted, there will be an option to “Treat this as a snapshot”, or some similar verbiage, where it will save a “snapshot” of the student's work for that assignment. The idea is that not everything is up for keeps, only the things that the teacher deems important. We can then utilize these “snapshots” as a collection to prove student learning.
So, we begin by creating the storage spaces then implementing the e-mail editors that will utilize both the Document Management piece and the Admin Work Storage piece. This way, user will be able to use their own Document Management to link files to emails (like pictures), and these files will be stored in the Admin Work Storage to preserve them. Note that there are fundamental differences between the storage types, the Document Manager is personal and used to manage your documents, while the Work Storage is used to store content for the school. Because of this, they will be treated differently, so that we may have multiple ways for users to connect their documents systems to the LMS and access different documents from different services, while the work storage will focus more on storing files to our own servers.
Both systems will revolve around a central SystemSetting class StorageSpaceSettings, which will be responsible for keeping all the bindings together and specifying where the system should store what. It will register two kind of classes, WorkStorage, which will be an abstract class that define the needed functions for all work that needs to be stored, and DocumentStorage, which will always be assigned to users, and will be used to provide documents. Whenever a document is attached to an announcement or area that requires file permanency, the file in question will be transformed into a WorkFile object that will be passed to the appropriate WorkStorage class, which will then be in charge of storing all the data in a permanent form. Likewise, when simply displaying information about a file, a DocumentFile object will be returned instead, so that the interface can interact with it. DocumentFile objects will not be stored.
For now, I will create 2 of each class: one for local and one for Google, so we will have four classes total: GoogleWorkStorage, GoogleDocumentStorage, LocalWorkStorage and GoogleWorkStorage.
I also made the WorkStorage and DocumentStorage be children of another abstract class LmsStorage, which allows me to consolidate some Livewire components and abstract quite a lot.
Applying them to Emails
So now that we have all these instantiations of where the files could becoming from and going to, let's implement them in something so we can see if our abstraction is going to work. I will still start with the Local Interface, and once I'm happy, I'll add the Google one and move into Integrators. I will not be putting this in as a setting, simply because the settings tabs are getting too crowded, so I'll add a menu under the “System” menu and call it “School Emails”.
Trying new things; Since this page is basically a full-page Livewire component and livewire has support for putting in full-page livewire components (and I really didn't want to write a controller for a single page and I hate putting in functions in the route files), I decided to try the feature out. It took a bit, but the magic that made it happen was this code:
public function render()
{
return view('livewire.utilities.school-emails-editor')
->extends('layouts.app', [ 'breadcrumb' => $this->breadcrumb ])
->section('content');
}Which tied in the component directly into my master layout. From here the following things need to be done in order to complete the feature:
- Create a simple selection-edit-interface, meaning a simple way to present your selections and edit them. I don't think there will be many emails sent through the system, so the selection are should not be that large.
- The component will need a full-featured editor capable of:
- Inserting the “tokens” provided by the
Mailable'savailableTokens()function. - Be able to interact with the
DocumentStoragedriver(s) in order to allow the user to select an image file to insert into the email.
- Inserting the “tokens” provided by the
- Create a way for the user to select files and attach them to the email.
- The user should be able to select any type of file to attach.
- The selected files will be put into the
email_storageWorkStorageand will be attached to the email. - The files will be available to delete, alter, etc by the user.
- Be able to preview the email
- Be able to send a test email.
- Be able to import the template from a different email in the system.
Overall, the largest apprehension in this list is the fool-feature editor. I plan on using what I've been using in FabLMS, which is tinyMCE (as opposed to CKEditor, which I use is DiCMS). It mainly comes from trying to figure out how to make the plugin do what I want in the editor, which means learning the editor's code basically.
A Detour into AI and the World
I also implemented the language-switching capabilities in this build and I've asked my amazing father, Federico Kalinec, to translate my project into Spanish. He's agreed to help and has done some translations already, so in his honor, I added an account for him to use so he can check what his work does and made the Spanish option for the language selector into the Argentinian flag.
Along with this, I also need to learn how to use AI. It's something that is too powerful to ignore and even though it seems to be plateauing, I don't think we've actually yet fully explored what we have yet. In order to do this, I will use Google's Gemini, simply because I already have a project set up with them, I'm already integrating their services into FabLMS and I don't want to pay for OpenAI. My goal is to be able to do two things with AI in my LMS:
- Be able to generate rubrics through a command
- This will allow a system admin to execute an artisan command
develop-rubrics - This artisan command will then crawl through the system's
Skills(bothCharacterSkillsandKnowledgeSkills) and create a rubric for each - The command will “remember” which knowledge skills it has generated rubrics for, so it can be stopped and restarted
- It will have options to re-do all the rubrics
- It will have options for the number of points and the assessment criteria.
- This will allow a system admin to execute an artisan command
- Be able to translate the system into different languages through a command
- The command will take in a language locale and translate all the translation files from the
enlocale. - The command will keep track of the translations created so it can continue at another time.
- The command will also create the translation file structure for the new locale if one does not yet exists.
- It will also add any missing keys to the new file.
- The command will take in a language locale and translate all the translation files from the
Note that none of these things will be usable by the users (but they will see the results) and for good reason. Accessing big-daddy AI costs money, and making your own AI server costs money. Since this is a project on the cheap, I will be using the cheap options. Google does give me some free, limited access and I plan to make use of it. This means that the amount of translations or rubrics I may be able to do at a time might be limited, so I will want to put in not just a throttler, but a way to “continue” if some process were to fail, so I don't have to start rebuilding all the rubrics or translations.
I will be using the Laravel (non-official) package Prism with the Gemini provider and acquired my Gemini key and tied it in to my existing project. Prism came with the Gemini driver already configured, all I needed to do was add a few lines to my .env and I was good to go.
My first test was beyond impressive. I created a prompt to an AI that did the following:
- Used a System Prompt to tell it that it was an educational specialist, gave it the text of my views on assessing that got from my Skilled Messaging post, and told it I will be providing it with a skill and they would generate the rubric. I gave specific instructions to make the rubric with the point system that is set in the config files, so it will be uniform.
- Used a view that extracted the information from a random skill to create the prompt
- Created a schema that would return a structured response for my rubric.
- Put the schema back into the skill and updated.
This is the result:

That's pretty impressive. The next this is to create a system that will keep track of which skill was updated. This is even easier to do, since I will go through all the Knowledge Skill in order of id and create a rubric. Once the skill is updated, I will save the latest id in a SystemSetting entry as completed. If I have to restart, it will get all the skill with id greater than the saved one. Also important is to create a backup! I don't need to do this over and over, just enough to get seeding data. In a real-world environment, you would need the ability to save this anyways. It would also be nice to have a soft backup to perhaps scrape for other data.
One of the first issues that I ran on Gemini is the idea of “thinking budgets” and “thinking tokens”. Essentially, since it's a higher reasoning model, it uses a feature called thinking, which analyzes the prompt in a more advance way. Thinking consumes thinking tokens, which you have about “1M per context window”, which I have no idea what it means. I decided to put a “budget” of 8,000, since the error said that in needed “at least 4971 (suggested: 7942 for comfortable margin)”. I will try this first, but there's always the alternative of using an older model, like the 2.0-flash instead of the 2.5. Using 2.0 should be faster and incur no costs, but the data will not be as good. I will also increase the number of points to 6, thus ranging from 0-5 to make it easier on calculations.
My goal is to fill in every Knowledge Skill in my system. But what about Character Skills? Well, it turns out that there are none! Now, I will add the feature that it will cycle through them, just for completion. This does beg the question if whether I should ask AI to develop my Character Skills, but I decided against it. Simply put, I figure that Character Skill might not be used in a real-world environment; If they were, then they would be closely tied to the school's mission and values, which my LMS has none as it is not a real school. It might be worth adding a few useless ones, but that can wait till the future and it will not need AI.
I will generate the rubrics on my development computer, then write a seeder that go through that folder and restore all the data. This way I can generate everything in my home computer, upload all the files to my server and then I no longer have to generate junk rubrics, just load them from backups. I also would like to see if other people are interested in these AI-generated rubrics, so I might post up something in Reddit. A lot of my thought on this process came from this post I posted to help me think. I anyone is reading this and wants to check it out, log into the system with the username/password staff@newroads.org/staff.
Once that is complete, I will conclude this detour, leaving the translation for another time.
Back to Storage
I started building the image insert, simply because that seemed like the hardest piece and it would get me learning tinimce. After quite a bit of struggle, I manage to add a button and call a livewire function. This led into the creation of the Document Browser, which is the first half of the document storage system. My goal with this component was to give a way for users to manage their files across platforms through a single, unified interface. I may change my mind, as google uses a nice interface too, but this way it's easier to build a driver for the Document Storage. I created the first driver, the LocaDocumentStorage driver, but I plan on also creating the Google one once I have this built.
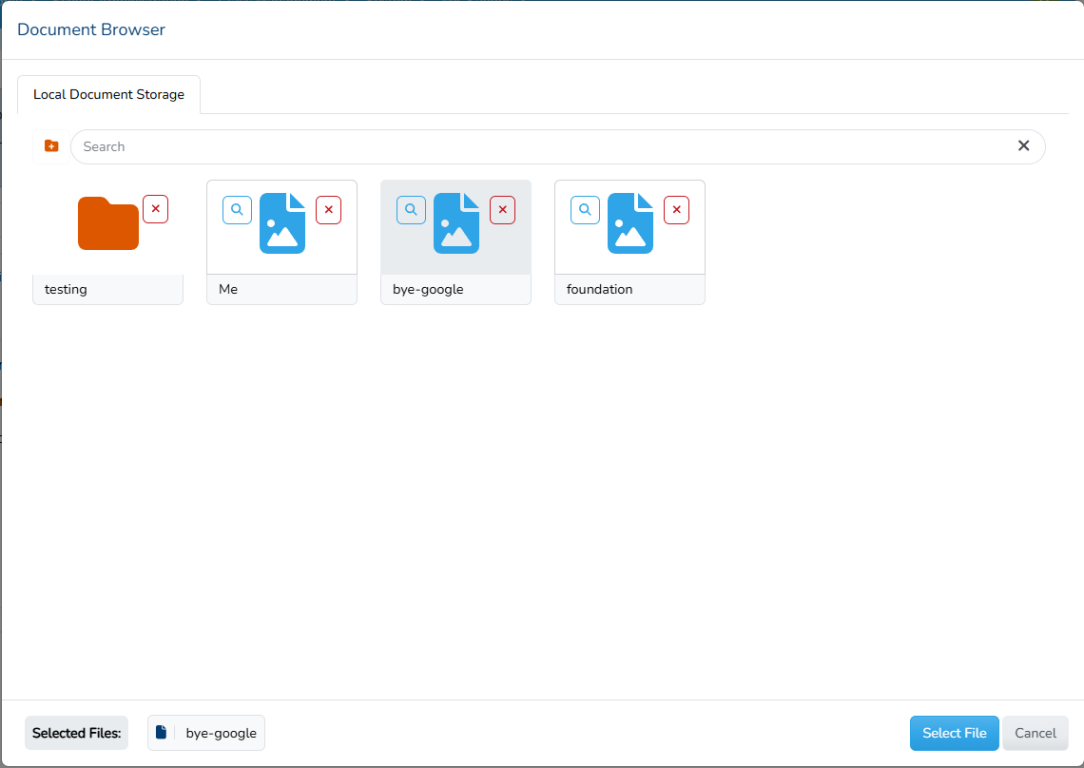
I struggled a bit on the definition of what exactly the purpose of this component is. This component is a way to access your files remotely on a ser. As such, it has to do it's own function calls to the driver to get the appropriate information. At this point, there is no mention of the other half, the Work Storage, and that is because they're completely separate. The Document Storage will also store work, on it's own instance and its own parameters and using a rather simple interface:
abstract class DocumentStorage extends LmsStorage
{
/**
* @param Person $person The person to get the storage from.
* @param array $mimeTypes The mime types allowed. If empty, all mime types are allowed.
* @return array An array of DocumentFile objects of all the files at the root of the storage.
*/
abstract public function rootFiles(Person $person, array $mimeTypes = []): array;
/**
* @param Person $person The person to get the storage from.
* @param DocumentFile $directory The directory to get the files from.
* @param array $mimeTypes The mime types allowed. If empty, all mime types are allowed.
* @return array An array of DocumentFile objects of all the files in the directory.
*/
abstract public function files(Person $person, DocumentFile $directory, array $mimeTypes = []): array;
/**
* @param Person $person The person to get the storage from.
* @param string $path The path to the file.
* @return DocumentFile|null The file object, null if it does not exist.
*/
abstract public function file(Person $person, string $path): ?DocumentFile;
/**
* @param Person $person The person to get the storage from.
* @param DocumentFile $file The file to get the parent directory of.
* @return DocumentFile|null The parent directory, null if it is the root directory.
*/
abstract public function parentDirectory(Person $person, DocumentFile $file): ?DocumentFile;
/**
* @param Person $person The person to get the storage from.
* @param DocumentFile $file The file to get the preview of.
* @return string An html string to display a preview of the file, assuming it is previewable.
*/
abstract public function previewFile(Person $person, DocumentFile $file): string;
/**
* @param Person $person The person to get the storage from.
* @param DocumentFile $file The file to delete.
* @return void
*/
abstract public function deleteFile(Person $person, DocumentFile $file): void;
/**
* @param Person $person The person to get the storage from.
* @param DocumentFile $file The file to change the name of.
* @param string $name The new name of the file.
* @return void
*/
abstract public function changeName(Person $person, DocumentFile $file, string $name): void;
/**
* @param Person $person The person to get the storage from.
* @param DocumentFile $file The file we're moving
* @param DocumentFile|null $newParent The new parent directory of the file.
* @return void
*/
abstract public function changeParent(Person $person, DocumentFile $file, DocumentFile $newParent = null): void;
/**
* @return bool True if the storage can persist files or folders, false otherwise.
*/
abstract public function canPersistFiles(): bool;
/**
* @param Person $person The person to get the storage from.
* @param string $name The name of the folder to create.
* @param DocumentFile|null $parent The parent directory of the folder.
* @return DocumentFile|null Returns the new folder created, null if the folder already exists.
*/
abstract public function persistFolder(Person $person, string $name, DocumentFile $parent = null): ?DocumentFile;
/**
* @param Person $person The person to get the storage from.
* @param UploadedFile $file The file that was uploaded
* @param DocumentFile|null $parent The parent directory to store the file under.
* @return DocumentFile|null Returns the new file created, null if there is an error
*/
abstract public function persistFile(Person $person, UploadedFile $file, DocumentFile $parent = null): ?DocumentFile;
/**
* @param Person $person The person to get the storage from.
* @param DocumentFile $file The file to download.
* @param array $preferMime Optional array of preferred mime types.
* @return ExportFile Contains the file data and metadata for the exported file.
*/
abstract public function exportFile(Person $person, DocumentFile $file, array $preferMime = []): ExportFile;
}Simply fill in the interface with your own file system driver and you get access to those files through the browser. The idea is not just that students and employees will be able to use whatever file system they want to use, but they can also connect to any other filesystems that you have a driver for (and a key, of course). The DocumentFile object is just really information abut where the file is stored and how to access it. We don't really deal with content until we convert it into a the equivalent for the Work Storage side.
But when does that happen? That's the question that I've been struggling with. The idea is that the Work Storage will only really be there as a file repository. It doe not need a file browser because we're not expecting the user to manipulate anything about the files or the structure. It is simply a pit that is used as storage so that any media attached to an object stays the same when that object is viewed, so that the historical record remains. But does it get removed? Well, we need to be able to remove or at least update it in most cases. For example, in the case of emails, which will get its own storage, if there are changes to the headers, or the school logos we will need to update them. We also want to keep it clean, so if we add an image to email, then delete it from the email, we want to remove it from storage, else we could end up with a bunch of different images that no none can remove.
There are cases where we do want to allow the user to remove files, such as for example, when attaching files to a class announcements. Mistake happen and maybe the worksheet they posted had a mistake and they would like to remove it and re-upload it. That will be done through a very simplified storage browser that will allow more types of files and their removal and small changes, such as the file name. There will be no directory structure that the user can see or interact with.
These files are called WorkFile objects and they're radically different than DocumentFile, most importantly is that they're stored in the database as well as in the storage. The process essentially follows:
- A
DocumentFileneeds to be stored - The appropriate
WorkStoragecontainer is determined. This is done by the app making the connections. An email would use an instance ofWorkStoragethat is tied to the email storages. - The function
persistFile(Fileable, DocumentFile)is called on theWorkStoragecontainer- Fileable is an object that can be linked in the database to a
WorkFile - The
WorkFileis used to locate the file and storage and person and it - The function
exportFile(Person $person, DocumentFile $file, array $preferMime)is called to get the actual file contents in some sort of format. - The
WorkStoragestores the file in its storage - The
WorkStoragethen creates and instantiates to the database the information about the file and the location of the file and bundles that into aWorkFileobject. - The
WorkFileis linked to theFileableobject - The
WorkFileis returned, including the URL of the file.
- Fileable is an object that can be linked in the database to a
It should be noted that all the WorkFile objects will be accessible via URL to any auth user, although each WorkStorage can make their own rules about how to download them or if they have permissions, since they will be called on to download the file. If there are multiple files then the above process will be iterated through each file or through its sister function persistFile(Fileable, DocumentFile[]). Also, adding folders is ok, however only the files will be copied, so the system will iterate through each file and subfolder and pull out the files to store.
Once that was built the editor part was quite easy. I created a plugin the added the button to the editor. One button makes a call to open the browser, which selects a single image file, and returns it to the editor. The editor adds the file to the storage, links it to the email and returns a WorkFile object to tinymce, which then extracts the URL and puts up the image in the editor. The neat piece of code came from this comment in stack exchange that explained how to check if an image was deleted then remove it from the server automatically.
Adding More Storage
I wanted to add another kind of storage so I can extend and test my code differently, so I decided to build the GoogleDocumentStorage driver that would interface Google Docs with my system. It was surprisingly easy, as all I had to do was write the Class methods in relation to Google and it just worked. I decided to make this a picker-only, meaning it is not set up to manage files, only to supply files. Goggle Docs can always export to PDF, so I made it to where, if it's an image file it will transfer correctly, but for a any other file it will try to convert into a PDF. I think I should put in more checks, especially for different kinds of files, but it is not really needed at this point, and it's something that I can always build later.
It was surprisingly easy to build the class. After it, it just worked and it interfaces just like local storage does, only with a bit more latency as it is querying another service. Now, in order to get access to these docs 2 things have to happen:
- Google Document Storage needs to be set up for as an option for either employees or students
- The user must login to their Google Account and grant permissions.
#1 was built into the system from the start, which is why you can select multiple sources as possible Documents. However, #2 only really works if the user has an auth with Google in order to log in, which only happens for the main account, or anything set manually and set to the correct email. This is useful if your whole institution uses Google Docs, but not if they don't (or use something different). In the case where they're not using it though, would it be beneficial to access Google Docs? say, from a private account?
Also, I found that I couldn't really build an equivalent WorkStorage Interface for Google, as the idea that all files would be held in a single account means that the system needs to be aware and be able to access that account. The correct way of doing this is not to provide the account username and password to the system, as it is a security risk since, especially for google, you can't really use oAuth and must use an app password instead. The correct solution is to create a service account in google that is able to access any account. Configuration for the service account is another beast though, so we are stuck with configuring each individual piece. If we want Google Documents we need oAuth everywhere, if we want a work storage we need a service account.
There is also a matter of security while showcasing this on the web. I'm not a big fan of letting people upload stuff to my server, but I do want to make this feature available. SO as a trade off I made it so that all files are deleted in all spaces every 15 minutes. If need be, of course, I'll nuke the droplet and reinstall from git.
What's Next?
Next is going back to what I was talking about two posts ago: Integrators. I may or may not ignore the wallet code, depending on how I feel like it. I would also like to build something that interfaces with my new storage system. Maybe start up the Learning Demonstrations code, although I would like to revisit my thoughts on that first. Similar with my class view code.
I would also like to add more tools to my AI system. For one, I would like to be able to re-generate a rubric by the push of a button. I would also like to start my work in AI translation. Perhaps even build a tool that will “clean up” my translation files with an option to fill in missing translations with AI.
I am exited about this release, because it will include the new Spanish translations files built by my dad, so I will update when I'm done.
